蒐集 Linux 的指令用法,主要是 case by case 而非指令的詳細用法。並且指令也不侷限於此處提到的用法。故使用者有興趣可深入查詢研究。
- 通用觀念
- 管道是由右向左建立起來的。複合指令正確時無虞;但錯誤時,便需知道從右邊過來可能已産生既定的結果(例如建立一個檔案)
- 管道/線,本身是無緩衝的,但指令之輸入端可能有,例如 sort,指令之輸出端可能沒有,例如 sort,ls。
- 變量:賦值時只以字串形式表示,取值時前綴$。myvar=ken; echo $myvar;
- $myvar 等同 ${myvar},後者更利於辨識。
- 可將命令執行結果賦予一變量,表示法:myvar=`date` 或 myvar=$(date)
- 注意等號兩邊不允許有空格,因為如 myvar = ken 會解釋成執行 myvar 帶二個參數。
- 可互動式地指定變量:read myvar,則 shell 會等待輸入,並賦予 myvar 該輸入值。可加 -t x 限時 x 秒。-p str 做提示。-n x 表允許最多 x 個字元。-s 輸入的不可視。若無 myvar,則會存入環境變數 $REPLY。
- 行內輸入重定向,command << 識別字串。接著可多行輸入,最後再以該識別字串結束/其本身不參與輸入。但不建議使用因其會打亂歴史記錄之格式。(參見後面 history 段落)。用法例如:
$> wc << some_str_id
> input_str_1
> input_str_2
> …
> some_str_id
$>
同理也建議不要使用例如,
$> echo “This is my
> dog
> and cat”
$> - 命令行變量:例如執行 ls -l -a -R,那麼會産生對應的暫存變量 $0,$1,$2,$3 各代表 ls,-l,-a,-R 依此類推,以供當下運用(請注意是執行當中才有,故主要用於 script file 內)。另有 $# 代表總共有幾個參數,不含指令本身。上例是 3。第十個以後表示 ${10} 以此類推。若使用 ${$#},則要改為用 ${!#}。
- $* 代表所有參數為一個整體。$@ 則代表所有參數,即參數 list。引用時,加上引號才能保有其原有的性質。
- $? 代表命令執行後的回傳值,其為 0 的話通常表示執行成功。
- shift 可將參數 list 左移出去,可 shift n,預設是 1。例如 cmd a b c,shift 2 將得到 $1==c。而被移掉的無法再回復。
- basename:basename /home/ken/a.txt 會得到 a.txt 字串
- 參考
- 參考
# 取得執行中的 script 的所在絕對路徑不容易,也沒有標準答案,請參考以下連結,
https://stackoverflow.com/questions/59895/how-do-i-get-the-directory-where-a-bash-script-is-located-from-within-the-script?page=1&tab=scoredesc#tab-top
https://stackoverflow.com/questions/4774054/reliable-way-for-a-bash-script-to-get-the-full-path-to-itself
https://unix.stackexchange.com/questions/11376/what-does-double-dash-mean
# SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
# SCRIPT_NAME=$( basename -- "${BASH_SOURCE[0]}" )
# shell script 新手必犯的錯誤是,該注意:1)執行者的身份與權限,2)執行的路徑指定。
有沒有前綴 sudo 是有差別的,sudo ./a.sh; 或 ./a.sh; 前者是以擬 root 的身份執行,故若 script 內有用到 ~/Desktop,則將是 root's;顯然錯誤。
故,使用絕對路徑便沒問題。除非謹辨每一行執行指令與路徑與身份的關係。
另外執行 a.sh 至少要指明相對路徑即便 $PWD 和 a.sh 在同一目錄下否則,bash 會找不到。即,> a.sh; (x); > ./a.sh; (o);
還有很重要一點,script 內難免用到相對路徑,但若用上 $PWD,則 $PWD 會變動/若用上 cd,代表著當下工作路徑。
若 a.sh 在 /home/ken/a.sh,
則初始時若 /home/ken/> /home/ken/a.sh 則 $PWD==/home/ken/;
則初始時若 /> /home/ken/a.sh 則 $PWD==/;
權限部份,要 chmod (u)ser/(g)roup/(o)thers/(a)ll + e(x)ecute 之後才能讓該身份執行該可執行檔。
> echo abc; echo "abc"; echo "'abc'"; echo '"abc"'; echo ''abc'';
依序為 abc, abc, 'abc', "abc", abc; 可知輸出字串的採用方式。且最後一筆可知前後各自先行配組故引號不被輸出。
另外也可用轉義字元 \。
注意上面第一行每個 abc 都是逐行列印,因為;代表按了 enter 執行。
> var=9
> echo "this is a $var" (o 9).
> echo "this is a \$var" (x $var).
> echo this is a $var (o 9).
> echo this is a \$var (x $var).
# 邏輯判斷之成立,是指執行行為完成沒有錯誤,通常代表值是 0,反之只要有錯誤或警告回傳非零則判斷式不成立。例外的是 until 之用法。
#
if logical_result_1; then
conditional_ops
elif logical_result_2; then
conditional_ops
elif logical_result_3; then
conditional_ops
else
conditional_ops
fi
## logical_result 可為例如 test $var 或 test command 或 [ condition ],
若 $var 為空字串或未指定值或 command 回傳執行不成功則都是 test failed。
condition 可有幾種比較子:數值用的,-eq -ge -gt -le -lt -ne;字串用的,= != < > -n(長度不為零或非未指定值) -z(長度為零或未指定值)。
但是例如 >,用在方括號內是必須使用轉義符號的。
數值用的比較子與字串用的不能混用。
## 檔案比較子 -op file
-d(a dir) -e(exists) -f(a file) -r(readable) -s(filesize>0) -w(writable) -x(execable)
-O(owner is current user) -G(group is current user)
file1 -nt file2(newer than),但須先確認檔案是否存在。前面的比較子都不需這一步。
file1 -ot file2(older than),但須先確認檔案是否存在。
## [ condition ] 擴展:[ cond1 ] && [ cond2 ] || [ cond3 ]
## 字串用的高級擴展:[[ condition_or_re ]],例如 if [[ $USER == r.* ]]; then
# 數值運算,不支援浮點運算:expr $var1 op $var2;
例如,
expr $var1 + 2
但可能的特殊字元最好加轉義字元,例如,
expr $var1 \* $var2
## 同義(類似 $(command) ):
var_r=$[ $var1 op $var2 ]; 此時就不需用上轉義字元了。
## 同義(高級擴展):
(( varn=$var1 op $var2 op ... ))
if (( $var1 op $var2 )); then
例如:
if (( $var1 ** 2 > 90 )); then
(( var2=$var1++ ))
可用的擴展運算子為,同義於 lang_c:
**(冪運算), a++, a--, ++a, --a, !, &&, ||, ~, &, |, >>, <<。
# case:同 lang_c 之運作模式。
case $var in
pattern1 | pattern2 )
command1;;
pattern3 )
command1
command2;;
* )
default_command1;;
esac
# for:注意上面的 case $var 和 for var。
for var in list; do
commands
done
例如:
for var in a b c d "e f" g h\'i j k; do
for var in $( cat $file ); do
for var in /home/ken/*; do
for var in /home/ken/* /home/kenny/*; do
for (( i=0, j=10; i<j; i++, --j )); do
# $IFS,預設為空格,tab,換行。更改之:
IFS.OLD=$IFS
IFS=$'\n' 或多個 IFS=:;.$'\n'
IFS=$IFS.OLD 用完後回復之
# while: 判斷式必須最後為偽才能跳出,成立則繼續執行。
while logical_result; do
commands
done
在 while 和 do 之間可為多個敍述,但最後一個要是判斷式其唯一供 while 判斷,例如,
while
echo -n "the next var is: "
echo $1
[ $# -gt 0 ]
do
# until: 判斷式必須最後為真才能跳出,不成立則繼續執行。同 while 只差在判斷式。
## 可從 done 之後將迴圈內的所有輸出重定向。例如 done | sort。
## break, continue 同 lang_c 概念,不過此還可以接跳出的層數;預設是 1,即 break == break 1。break 2 表跳出第二層。
# getopt:搭配 case-switch 使用。將 real-parameters 按 fmt-optstring 解析出選項及參數
getopt -q fmt-optstring real-parameters
-q 抑制若無法解析的錯誤訊息
: 代表有接一個參數。也只能一個,not :: or more。
解析完成後輸出一行結果。無法解析引號中的空格。輸出選項會帶減號,用字串 -- 分隔選項及參數。
我們透過 set -- $( getopt fmt-str "$@" ) 來代換原始參數列。
例如,
getopt ab:cd "-a -b test1 -c -d test2 test3" (x) 不能有引號
getopt ab:cd -a -b test1 -c -d test2 test3 (o)
getopt ab:cd test2 -d test3 -c -b test1 -a 會輸出 -d -c -b test1 -a -- test2 test3
# getopts:逐個單元解析,且可識別引號及其內空格,選項與其參數間不必有空格,選項輸出不含減號。
須搭配 while 使用因每解析一個會回傳 0 且有環境變數被暫存,直到解完回傳非零。
惟須留意選項與剩餘參數須分左右兩邊。
getopts :fmt-optstring var
前綴 : 等同 getopt -q,
解析出的選項放在 $var(若有接的)參數字串放在 $OPTARG,當前的索引放在 $OPTIND。透過最後的索引值處理剩下的參數。
# 標準輸出入重定向:識別元 0, 1, 2 為標準。3 至 8 為自訂用。
例如:
> ls -la /home /home/jen/ 1> a1.txt 2> err.txt 或
ls -la /home /home/jen/ 1>> a1.txt 2>> err.txt 或
ls -la /home /home/jen/ &> a1.txt
分別是,1,2 分別導出。1,2 分別導出以追加。1,2 導出到同一處。識別元與導出子中間不能有空格。
例如:
在 script 中要將某輸出暫時導至 2,
echo "this is an error." >&2
在 script 中要將輸出永久導出,使用 exec,
exec 2> err.txt
則若 exec 2> err.txt; echo "err!" >&2; 則 err! 便也輸出至 err.txt。
輸入:
exec 0< somefile.txt
使用自訂:例如:
exec 3> test3.txt; echo "Output to the 3" >&3; 則導到 test3.txt。注意必須使用 >&。後續導出會以追加的方式,並且無 >>&3 這種用法。因為一旦定義,檔案便被開啟,故是以追加的型式。是故,exec 3> 和 exec 3>> 運作一樣,但前者會將開檔前之該檔內容清空。
恢復技巧,例如:
exec 3>&1; 將 3 導到 1,此時 3 是標準輸出。
exec 1> test.txt; 此時 1 已導到檔案,不過 3 仍維持標準輸出。
exec 1>&3; 1 回復成標準輸出。
同理輸入恢復:
exec 4<&0; exec 0< input.txt; exec 0<&4;
關閉:重定向到 &-。例如 exec 3> test; echo "x" >3; exec 3>&-;
# 使用 mktemp,例如:
tmpdir=$( mktemp -t -d mytmpd.XXXXXXXX ); X 須大寫,-t 於系統暫存目錄下,-d 建目錄。
cd $tmpdir;
tmpf=$( mktemp mytmpf.XXXXXXXX ); 創建檔案。
exec 3> "$tmpf"; 3 導至檔案。
echo "to 3" >&3;
echo "use tee" | tee -a "$tmpf"; -a, append. tee 同時導至標準輸出及導至檔案。
exec 3>&-;
rm "$tmpdir/$tmpf";
rmdir $tmpdir;
netcat
透過 TCP/IP 傳送封包,使用者自訂其內容。可建立傾聽端(服務端)(當該埠是未被佔用的),也可建立傳送端。
在本地端的 8088 埠(port)建立傾聽端(listener),ctrl-c 結束或單一 session 傳完也自動結束掉。
- netcat -l -p 8088
建立傳送端,對象是本地的 8088 port
- netcat localhost 8088
建立後,例如輸入 a,則 listener 會 dump 出 a。
測試
因為我們本地端已有 web server,故建立 sender,並發送 GET request 來查看回應。
但我現在更希望知道 GET request 長怎麼樣,故,我們先停止 web server,利用 firefox 發送來攫取:firefox 需鍵入網址 http://localhost/
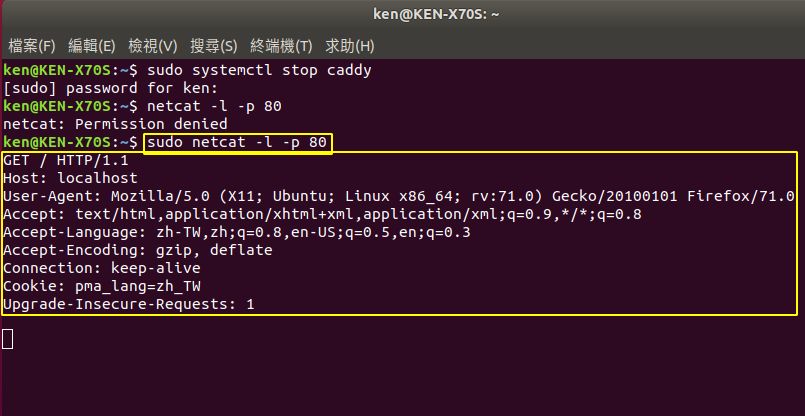
抓到之後,再重新啟動 web server 後, 建立 localhost:80 sender,再把剛複製的 GET request 貼上,得到 web server 的回應如下
- netcat localhost 80
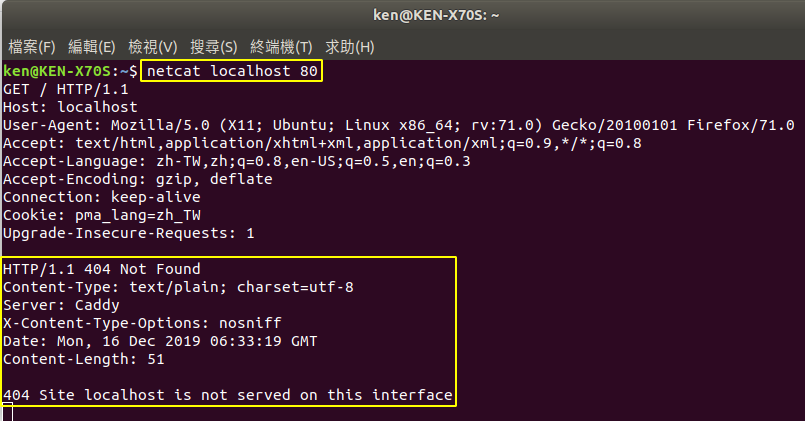
- 參考資料
- -l listen
- -p port
- -u UDP instead of TCP
- https://askubuntu.com/questions/443227/sending-a-simple-tcp-message-using-netcat
- https://unix.stackexchange.com/questions/121230/nc-bind-failed-address-already-in-use/121244
- https://ubuntuforums.org/showthread.php?t=2260190
- https://unix.stackexchange.com/questions/366913/problem-running-a-web-server-in-oracle-vm-virtualbox-with-port-forwarding
history
其實對於新手或老手,history 都有相當多的用處。因為就算老手,仍會接觸到新的指令操作。又或是記性不好的使用者,像筆者就是。再或是追查何時下過什麼指令等等。新手會慢慢查覺 history 的諸多好處。
必要在 .bashrc 加入以下這三行,
HISTSIZE=-1
HISTFILESIZE=-1
export HISTTIMEFORMAT=”%F %T ” (注意雙引號及其後的空格)
- 在安裝 Ubuntu 時提到,bash shell 預設 history 就是不含時間戳記的下過的指令的記錄。其儲存在 user home 下的 .bash_history 文字檔案內,可 cat 出來看看。因此,在那篇就變更預設,成不限筆數及加入時間戳記。
- shell 下下達 history 後,即可 dump 出來編上行號的指令歴史記錄。可下 “!行號”以執行該行指令。
- 當時下過的指令會先暫存,若同時使用數個 shell,當最後一個 shell 關閉後,才會將最後一個關閉的 shell 所下過的指令寫入 .bash_history,其它先關閉的不會儲存。
- 預設的記錄會長得像這樣:
cd ~
cp .bash_history ./Desktop/33.txt - 當加入時間戳記後,.bash_history 內容的每一筆記錄會長得像這樣
#1577514000
cd~
#1577514019
cp .bash_history ./Desktop/33.txt
第一行是時間戳記,第二行是指令。 - 小技巧,僅經驗非肯定,若不想讓接下來輸入的那行命令記入 history,則只要開頭留有空格,便不會被加入。
補充:
可參考此連結,https://stackoverflow.com/questions/6475524/how-do-i-prevent-commands-from-showing-up-in-bash-history
另外,常有機會持續嘗試某指令導致不必要的被記錄下來;故可先下 HISTIGNORE=’*’,那麼接下來所有鍵入者皆不記入 history。之後重開 terminal or 設 HISTIGNORE=’ *’,即回復。 - 本節旨在清理 history,將 .bash_history 中所有重覆下過的相同指令移除(例如,幾千筆記錄中,只會有唯一的一筆 ls -la,是不是很好玩)。我們該如何為之?重點不是清理,而是學習運用指令達到我們的目的。
- 當不含時間戳記時:
- cat -n .bash_history | tr -s [:blank:] ” ” | sort +1 -u | sort -n | cut -d ” ” -f3- (請注意雙引號字元)
- 其中:
- cat -n .bash_history 將記錄檔中的每一筆都加上流水號,我們目的是定序
- tr -s [:blank:] ” “,將 [:blank:],其代表“空白字元”,其包含 space & TAB,轉成“ ”空白字元,並且(-s 的意思)連續出現的空白字元,縮減成一個,例如“ _ _ _ _ _ _”有六個 space,刪成“ _”只有一個 space (我們在每個空白符號後多加了個“_”不然使用者看不出什麼)
sort +1 -u:一行中由空白字元分隔出若干個 field,例如 “just do it”有三個 fields,依序是 just,do,it。sort,排序,預設是由左而右逐個字元與其他行做比對。+1 指的是略過第一個 field,從第二個 field 開始排序。-u 是指,所有出現相同的,只留一筆。
因此,至此,已清除重覆者,但時間順序已亂掉,我們由一開頭的定序,再排序一次,便可排回時間順序。sort -n 指的是從第一個 field 起以視為數字的形式來排。 - cut 預設分隔符號是 TAB。我們以上使用 ” ” space,所以 -d ” ” 表示將 cut 認得的分隔符號換成 space(這表示我們處理的字串中也只能有 space 不能有 TAB,否則我們自己會亂掉。就這是為什麼我們開頭要把所有空白字元全轉成 space)。並且 cut 每遇到一個分隔符號便會累計個數。-f 表示從哪個 field 開始剪下。3- 表示從第三個 field 及以後的剪下保留。
最後導出入另一個檔案便是不重覆的歴史記錄了。 - 當含時間戳記時,只要將相鄰兩行合併,就回到第一個問題了,使用者可嘗試看看。
- 將相鄰兩行合併:xargs -n2 -d’\n’
- 將合併的再分開:sed ‘s/\(#[0-9]*\) \(.*\)/\1\n\2/’
- cat .bash_history | xargs -n2 -d’\n’ | cat -n | tr -s [:blank:] ” ” | sort +2 -u | sort -n | cut -d ” ” -f3- | sed ‘s/\(#[0-9]*\) \(.*\)/\1\n\2/’(請注意單雙引號字元)
- | 稱之為管線,將前一段指令的執行的標準輸出結果導到下一段指令做為輸入。若使用者的結果有誤,可逐段執行先觀看其結果符不符合預期。
- 當我們欲 merge 多份 history 時,因時間可能會重疊,在多份檔案 cat 在一起後,只需將上列中 sort -n 改成 sort +1,即可。再來,應會有不少指令(因 tab 補全的功能),會包含有 trailing space,因而結果將有些重覆/差在 space,不唯一,故,綜合以上,我們最終的指令如下示例,
(20230430 補充並說明,下一行的示例未完整,完整者在最後:沒找到 sort +number 的說明,不過已確認過 “+number” 就是 offset 的意思。此外,最後的示例在 tac 之前新追加的 sort +1,目的是若有多份 history 若來自於不同主機或使用者等,merge 起來後再來處理時,則須先對時間排序,反之只有一份時,時間業已序;亦即若無此新追加,便不能保證相同指令出現在最近的時間當多份 merge 時。此補充是最後加的,即此功能已驗證過許久了現再作追加,應可放心使用之。)
cat /home/ken/.bash_history | xargs -n2 -d'\n' | cat -n | tr -s [:blank:] " " | sed 's/[[:blank:]]*$//' | sort +2 -u | sort +1 | cut -d " " -f3- | sed 's/\(#[0-9]*\) \(.*\)/\1\n\2/' > $TMPFILE
參考資料:
https://unix.stackexchange.com/questions/102008/how-do-i-trim-leading-and-trailing-whitespace-from-each-line-of-some-output
https://stackoverflow.com/questions/3134791/how-do-i-remove-newlines-from-a-text-file
https://www.grymoire.com/Unix/Sed.html
# 因此,我們可以做一個將歷史記錄瘦身的 script file;請記得這一行須拿掉。
# (本段移除更新在下方。)- 再更新,
- 以上做法,仍是不夠,
- 因為記錄檔內可能會出現空指令,即,造成相鄰兩個時間標記之間,沒有指令,
- 故如此將造成整個處理錯亂,
- 甚者,我們假設會發生有多個時間標記相鄰在一起,那麼,這樣的情形,都必須被剩一個時間標記所取代,
- 而以下指令,便須前綴追加,其應是可處理正確,但此時筆者非百百肯定。不過也說明如下:
- sed 預設行為是只讀一行進來做代換,行尾的換行符號將被捨棄,直到該行處理完成,輸出並附加換行符號,再做下一行。故所處理者若要包含換行符號,便要使用指示的指令如下述。
- 其中,比對過的不符合者將直接被排出,符合者將會進入 pattern space 以做後續的代換,而 g 便是當成功第一筆,則還要繼續處理。
- :a;
label a - N;
在當前的處理下,再多讀下一行,換言之若來源只有一行將會直接結束掉。 - $!ba;
若還未發生遇到最後一行,則 branch to a;換言之,若最後一行也讀進來了,便不 branch,亦即,全檔載入,才開始代換。 - :c;
label c - tc;
to c
筆者不確定的地方就是在此,故說明僅供參考,
g 就是全域代換;那麼未進入 pattern space 者直接排出,已在 pattern space 且代換過者,其尚留在該空間,以再次被處理,並直接跳回處理搜尋取代的開頭,故,才能確保任意個相鄰重覆者最後只剩一筆。故相對地,可試著拿掉 tc; 看看結果差異為何。 - [[:space:]]
其有包含到換行符號。
而之所以要兩個中括號,是因它代表著不止一種可能,亦即,[:space:] 代表 \n, \space, \tab 等,故我們 OR 起來便需再加中括號,
[ \n \| \space \| \tab ]。 - 以下再插入一個 tac 命令。若使用 sort -r,其僅將排序結果再倒轉而已。而排序 -u 之預設行為,會保留最先出現的那筆,也就是最舊那筆。因此,此加入的 tac 便是保留最遲出現的唯一那筆。
- 補充說明,sed,
sed ‘:a;N;$!ba;s/\n\n\+/\n\n/g’
當我們要將連續多行空白行縮減成一行空白行時的用法。
其中,不能分開執行,即,sed ‘…’ | sed ‘…’;因為前管道的輸出又會將換行輸出,所以須在同一指令下跑。
再來,因為非空白行本身就包含了一個結尾換行字元,所以上述用法似乎是較好的做法,即,使用 tr -s,應是無法達成要求。 - 承上,再假如,我們不僅要把多行空行縮減成一行空行外,若存在連續非空行,且我只想保留連續非空行兩行以上,即單一行非空也要刪除,那麼承上的指令需改寫之外加下一行指令如下/至少;有興趣可自行玩玩看。
sed ‘:a;N;$!ba;s/\n\n\+/\n\n\n\n/g’;刪除空行外預留至少的空行;
sed ‘:a;N;$!ba;s/\n\n[^\n]\+\n\n/\n\nR\n\n/g’;單一行非空行被刪除,用 R 表示,接續如下再刪空一次;
承上;
全部合起來如下一行完整指令:
# 將連續多行空行縮減成一空行,並且將單一行非空行刪除。注意會有最後一行未處理到,及第一行可能未處理到。
cat in.txt | sed ':a;N;$!ba;s/\n\n\+/\n\n\n\n/g' | sed ':a;N;$!ba;s/\n\n[^\n]\+\n\n/\n\n\n\n/g' | sed ':a;N;$!ba;s/\n\n\+/\n\n/g'# treat the cases like,
# #1234 #5678
# #1234
# #5678
# #9012
# #3456
sed ':a;N;$!ba;:c;s/\(#[0-9]*\)[[:space:]]*\(#[0-9]*\)/\2/g;tc;'#!/bin/bash
# !!!for new history record only; otherwise old records will gone.!!!
# need to set the following 3 lines in .bashrc.
# HISTSIZE=-1
# HISTFILESIZE=-1
# export HISTTIMEFORMAT="%F %T "
# if ran failed, change $( whoami ) to your username.
# !!!your $> history; must be in this form.!!!
# 4709 2023-02-07 15:05:03 diff 001.txt .00MyHistBackup.sh
# 4710 2023-02-07 15:05:40 diff --color 001.txt .00MyHistBackup.sh
# 4711 2023-02-07 15:08:04 ls -la
# 4712 2023-02-07 15:10:40 vim 001.txt
cat /home/$( whoami )/.bash_history | sed ':a;N;$!ba;:c;s/\(#[0-9]*\)[[:space:]]*\(#[0-9]*\)/\2/g;tc;' | xargs -n2 -d'\n' | grep -v -q '^#.*'
if [ $? -eq 0 ]
then echo "Format out of order, please check first"
exit 1
fi
if [ "$EUID" -ne 0 ]
then echo "Please run as root"
exit 1
fi
TMPFILE=`mktemp /home/$( whoami )/00tmp.XXXXXXXXXX` || exit 1
cat /home/$( whoami )/.bash_history | sed ':a;N;$!ba;:c;s/\(#[0-9]*\)[[:space:]]*\(#[0-9]*\)/\2/g;tc;' | xargs -n2 -d'\n' | cat -n | tr -s [:blank:] " " | sed 's/[[:blank:]]*$//' | sort +1 | tac | sort +2 -u | sort +1 | cut -d " " -f3- | sed 's/\(#[0-9]*\) \(.*\)/\1\n\2/' > $TMPFILE
cp --remove-destination /home/$( whoami )/.bash_history /home/$( whoami )/.bash_history.bak
cat $TMPFILE > /home/$( whoami )/.bash_history
rm $TMPFILEinotify
- https://github.com/rvoicilas/inotify-tools/wiki
- https://stackoverflow.com/questions/47673447/inotify-linux-watching-subdirectories/49345762#49345762
- https://github.com/tinkershack/fluffy
netstat
- netstat -nputw
以數值的形式(n,其避免了伴隨可能的長程的 DNS 查詢)列出所有 UDP(u),TCP(t),和 RAW(w) 對外的連線(w 相對於 l 和 a),並包含了使用它的程式(p)。外加 c 參數的話可持續更新。
列出手動安裝的套件
- 筆者搜尋到一種方法,其目的毌待贅言。
- comm -23 <(apt-mark showmanual | sort -u) <(gzip -dc /var/log/installer/initial-status.gz | sed -n ‘s/^Package: //p’ | sort -u) (注意引號)
更新,如果這支檔案不存在 initial-status.gz(在或不在都有可能,若在,則下式 installer-journal.txt 不在),那麼上式應該不管用了,使用下式,列出已手自動安裝的套件。
sort -u <(apt-mark showmanual) <(cat /var/log/installer/installer-journal.txt | sed -n 's/.*Unpacking \([a-z0-9A-Z-]*\)[:\|[:space:]].*/\1/p')- 另外,以下這支 shell script 則會撈出在本機的安裝情況。
- 若是不加參數,則所有涉略過的套件,包含安裝更新移除的情況都會列出來。
- 參數則是接套件名稱,可部份名稱,也可不止一個參數。則除上述列出外也會針對所指定的再列細節出來。
RamDisk
- 對於頻繁存取硬碟的應用程式我們可以創建 ramdisk 讓它使用以延長磁碟壽命。速度的提升自不在話下。
- ramdisk 的空間大小,當然相依於所安裝的 ram 的空間大小。ram 留個 4 GB 給系統用應已足夠;不過還是得依實際情況而定。而剩下的可挪為 ramdisk 之用。但使用 ramdisk 並非常態,除非必要。
- 筆者的 ram 有 16GB,有時抓些影片會使用 emule。故跑它時會建立 10 GB 的 ramdisk 空間給它用。
- 先建立一個目錄,做為 ramdisk 的映射目錄。因只是儲存目的,所以設最低權限
- sudo mkdir /mnt/ramdisk
- sudo chown nobody:nogroup /mnt/ramdisk
- sudo mount -t tmpfs -o size=10240m tmpfs /mnt/ramdisk
- 若宣告上超出 RAM 實際的大小,是不會造成問題的,但此時硬碟空間也用上了。故量力而為。
- 若要卸載 sudo umount /mnt/ramdisk
- 在 ramdisk 中的資料,應可理解只要卸載或關機,就會消失不見。
- 以下是另一階段,視需要再使用。
- 若要每次開機都自動掛載,則編輯 /etc/fstab 這份檔案,底下加入一行:
- tmpfs /mnt/ramdisk tmpfs rw,size=10G 0 0
- 又在此前提下,我們應是會想要在關機前自動備份 ramdisk 中的所有檔案,那我們就要做一個服務,在開機時將備份資料夾 ramdisk_backup 中的所有檔案複製到 ramdisk,關機前將檔案備份從 ramdisk – > ramdisk_backup:
- sudo mkdir /mnt/ramdisk_backup
- 接著建立編輯服務檔,如下段落,注意須把 ken 改成您登入的使用者名稱
- 而假設有某 this_one.service 相依於需使用該 ramdisk,則需加入 Before=this_one.service,以確保同步及 ramdisk 已 ready。同時必須在 this_one.service 中也加入 After=this_ramdisk.mount 和 Requires=this_ramdisk.mount。其中 this_ramdisk.mount 的名稱由此指令查詢 systemctl list-units –type=mount(注意 – -t。通常是路徑再把反斜線改成 dash,例如 /mnt/rd/,mnt-rd.mount)
- sudo gedit /lib/systemd/system/ramdisk-sync.service
[Unit]
Description=ramdisk backup service
Before=umount.target this_one.service
[Service]
Type=oneshot
User=root
ExecStartPre=/bin/chown -Rf ken /mnt/ramdisk
ExecStart=/usr/bin/rsync -a /mnt/ramdisk_backup/ /mnt/ramdisk/
ExecStop=/usr/bin/rsync -a --delete /mnt/ramdisk/ /mnt/ramdisk_backup/
ExecStopPost=/bin/chown -Rf ken /mnt/ramdisk_backup
RemainAfterExit=yes
[Install]
WantedBy=multi-user.target- 接著啟用這個服務 sudo systemctl enable ramdisk-sync.service
- 如此,您便隨時都擁有 ramdisk。不過得注意,萬一系統不正常關機,可能該次變更的資料就會流失。
- 參考資料:
- https://www.golinuxcloud.com/run-script-with-systemd-before-shutdown-linux/
- https://docs.observium.org/persistent_ramdisk/
- https://blogs.oracle.com/linux/post/mirroring-a-running-system-into-a-ramdisk/
- https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/system_administrators_guide/chap-managing_services_with_systemd
- https://unix.stackexchange.com/questions/246935/set-systemd-service-to-execute-after-fstab-mount
- https://askubuntu.com/questions/1024916/how-can-i-launch-a-systemd-service-at-startup-before-another-systemd-service-sta
- https://unix.stackexchange.com/questions/236953/fsck-script-location/236968#236968
rsync
類似 cp 指令,其目的是用於備份檔案,故會有此性質的功能。
- 指令:rsync <options> <source> <destination>
- 用法,例如 rsync /tmp/1.txt /home/ken/,把 1.txt 複製到 ken 的家目錄下,而原本 1.txt 的 timestamp 不會被延用在新的 1.txt,其 timestamp 會使用複製當下的時間
- 參數選項:
- -z ,啟用壓縮,但並非是壓縮出結果,而是複製過程中做壓縮,以加速複製。建立的目的地檔與來源一樣,並沒有壓縮。
- -r ,recursive,該指定目錄下的所有(東西)檔案/目錄/子目錄,都會備份到目的地
- -a ,archive,歸檔封存,其 timestamp 會保留原始的,不會變更成最新的時間,此外,已內俱 -r 的性質故不需加指定 -r,以下為它已內俱的性質:Recursive mode,Preserves symbolic links;即連結檔一樣會被複製,Preserves permissions;即檔案模式會被複製保留著,Preserves timestamp,Preserves owner and group;即保留擁有者名稱。
- -d,只複製目錄,略過檔案
- –delete,刪除,若目的有,但來源沒有,則刪除目的該檔。(注意是 – -d)
- –existing,只複製目的地有的檔案,即若來源有但目的地沒有的,不做複製(- -e)
- –progress,顯示複製進度(注意是 – -p)
- -u,update,只更新檔案。即若目的檔比來源新(timestamp),將不會被更新。
- -v ,verbose,即會顯示複製過程細節,便於讓使用者觀察以防範出錯而不知所措。
- -e + <shell-keyword>,例如 -e ssh 表示以 ssh shell 做背景登入並 rsync。結束自動登出
- -i,複製後顯示來源與目的的差異,即有哪些被更動了。結果會以旗標顯示,共有九個點,例如:
- f 它是檔案
- s 大小改變
- t 時間戳記改變
- o 擁有者改變
- g 群組改變
- 來源或目的都可以是遠端的,以 $user@$hostname:$path 來指定,例如:
- rsync -avz /root/temp/ ken@example.com:/home/ken/temp/
- 若要走 ssh 通道,則加 -e ssh 指示以 ssh 終端做登入:
- rsync -avz -e ssh /root/temp/ ken@example.com:/home/ken/temp/
- 非預設的 port,使用 5900 的話,
- rsync -avz -e ‘ssh -p 5900’ /root/temp/ ken@example.com:/home/ken/temp/
- 例子:
- rsync -zvr /var/opt/installation/inventory/ /root/temp/
- 壓縮傳輸,顯示細節,並遞迴目錄底下的所有東西,新檔不繼承舊檔的屬性。
- rsync -zva /var/opt/installation/inventory/ /root/temp/
- 壓縮傳輸,顯示細節,並遞迴目錄底下的所有東西,舊檔案屬性全被保留到新檔案。
- rsync -azvp –delete -e ‘ssh -p5900’ /home/ken_1/uploads/ ken_2@example.com:/home/ken_2/uploads/(注意是 – -delete)
這個範例筆者遭遇到問題,註記參考如下,
https://bobcares.com/blog/rsync-error-protocol-incompatibility/ - 其他:自動化,當某目錄下檔案有變更時,
連結:https://github.com/lsyncd/lsyncd
範例:https://www.server-world.info/en/note?os=Ubuntu_16.04&p=lsync
apt
- apt policy
列出 repositories - add-apt-repository
加入 ppa
add-apt-repository ppa:PPA_REPOSITORY_NAME/PPA
移除 ppa
add-apt-repository –remove ppa:PPA_REPOSITORY_NAME/PPA (注意- -r)
例如列出的 repository 中某一行如下,
http://ppa.launchpad.net/videolan/master-daily/ubuntu bionic/main amd64 Packagesrelease v=18.04,o=LP-PPA-videolan-master-daily,a=bionic,n=bionic,l=VLC Daily Build of master branch,c=main,b=amd64origin ppa.launchpad.net
則如下下法:
add-apt-repository –remove ppa:videolan/master-daily(注意- -r) - apt update
更新 repositories 資料庫 - apt list
列出所有已知套件 - apt list –installed(注意 - -i)
列出已安裝的套件 - apt install PACKAGE-NAME(s)
安裝套件 - apt install –reinstall PACKAGE-NAME(s)(注意 – -)
- 重新安裝已安裝套件
- apt upgrade PACKAGE-NAME(s)
升級套件 - apt remove PACKAGE-NAME(s)
移除已安裝的套件 - cat /var/log/dpkg.log | grep “install.*openssh”(注意雙引號)
顯示與所指定(此例為 openssh)相關已安裝的套件的安裝時間及名稱 - ppa 相關的用法
https://askubuntu.com/questions/307/how-can-ppas-be-removed - deb 安裝兩步驟:通常安裝時會有相依性問題而終止,再下第二行指令以修正。
sudo dpkg -i package_name.deb
sudo apt -f install - apt 部份說明文件
- 在 /etc/apt/sources.list 中是存放正式的 ubuntu packages lists 連結,可直接修改該檔新增。我們若透過 ppa,或 ubuntu-update ap 加入 list,會新增檔案於 /etc/apt/sources.list.d/ 中;不使用或連結失效可從中直接移除。
- 加入 sources list 後,apt update,若有 secure issue,disabled by default 的問題,可在該行加入;如下例,
deb [trusted=yes] http://ppa.launchpad.net/pipewire-debian/pipewire-upstream/ubuntu/ hirsute main
又或是下 apt update –allow-unauthenticated(注意 – -allow) - 執行 apt update,會更新此目錄下的所有檔案,我們可因此作 refresh。如下說明:
https://unix.stackexchange.com/questions/217369/clear-apt-get-list - apt list 的其他疑問連結:
https://askubuntu.com/questions/58364/whats-the-difference-between-multiverse-universe-restricted-and-main
https://askubuntu.com/questions/732985/force-update-from-unsigned-repository
https://askubuntu.com/questions/1373514/can-there-be-any-issue-if-i-edit-sources-list-and-jump-between-ubuntu-releases
Python 不同版本中的切換成 active
- 先加入 ppa
sudo add-apt-repository ppa:deadsnakes/ppa - 接著安裝其他版本的 python3
- 顯示當前 active 的 python3
python3 -V
python3 –version(注意 - -v) - 建立 python3 的所有已安裝版本的切換群組,python3.6 & python3.9
sudo update-alternatives –install /usr/bin/python3 python3 /usr/bin/python3.6 1(注意 - -i)
sudo update-alternatives –install /usr/bin/python3 python3 /usr/bin/python3.9 2(注意 - -i) - 執行切換
sudo update-alternatives –config python3(注意 - -c) - 檢查版本
- 最後須注意 Ubuntu 18.04 使用 python3.6 維持系統的運作。切換成更新的版本將造成一些程式或系統運作上的異常,故確定要使用更新的版本請參考以下連結
- https://python.tutorials24x7.com/blog/how-to-install-python-3-8-on-ubuntu-1804-lts
ssh/scp speed test
抓到了一份 scp 的速度測試,筆者對其內容並非全部了解,但也做了些許雜漫地修改。並不保證其正確性與準確性與參考度。僅供參考。
#!/bin/bash
# scp-speed-test.sh
# Author: Alec Jacobson alecjacobsonATgmailDOTcom
#
# Test ssh connection speed by uploading and then downloading a 10000kB test
# file (optionally user-specified size)
#
# Usage:
# ./scp-speed-test.sh user@hostname [port [test file size in KB]]
#
ssh_server=$1
test_file="scp-test-file"
# Optional: user specified test file size in kBs
if test -z "$3"
then
# default block size is 512KB, 10MB
default_size=10000
test_size="512"
count_i=`expr $default_size / 512 + 1`
else
default_size=$3
test_size="512"
count_i=`expr $3 / 512 + 1`
fi
# Optional: user specified port
if test -z "$2"
then
# default port 22
test_port="22"
else
test_port=$2
fi
# generate a 10MB file of all zeros
echo "Generating $default_size kB test file..."
##dd if=/dev/zero of=$test_file bs=$(echo "$test_size*1024" | bc) count=1 &> /dev/null
dd if=/dev/urandom of=$test_file bs="$test_size"K count="$count_i" &> /dev/null
# upload test
echo "Testing upload to $ssh_server..."
up_speed=$(scp -v -P $test_port $test_file $ssh_server:$test_file 2>&1 | \
grep "Bytes per second" | \
sed "s/^[^0-9]*\([0-9.]*\)[^0-9]*\([0-9.]*\).*$/\1/g")
up_speed=$(echo "($up_speed*0.0009765625*100.0+0.5)/1*0.01" | bc)
# download test
echo "Testing download from $ssh_server..."
down_speed=$(scp -v -P $test_port $ssh_server:$test_file $test_file 2>&1 | \
grep "Bytes per second" | \
sed "s/^[^0-9]*\([0-9.]*\)[^0-9]*\([0-9.]*\).*$/\2/g")
down_speed=$(echo "($down_speed*0.0009765625*100.0+0.5)/1*0.01" | bc)
# clean up
echo "Removing test file on $ssh_server..."
ssh -p $test_port $ssh_server "rm $test_file"
echo "Removing test file locally..."
rm $test_file
# print result
echo ""
echo "Upload speed: $up_speed kB/s"
echo "Download speed: $down_speed kB/s"
find
查詢廣域 ip
- wget -qO- http://ipecho.net/plain ; echo
- https://ifconfig.co/
- https://www.ez2o.com/App/Net/IP
修復 root 檔案系統
- 開機時,出現 grub 開機選單時,按 e 進入編輯
- 在 linux 那一行追加 break=mount
- 按 F10 重新開機便會進入 initramfs
- 執行 fsck -f /dev/sdxx
- 離開
- 參考
比對兩目錄之內容之異同
- sudo find ./ -exec stat -c ‘%A %F %g %u %s %Y %n’ {} \; | sort +6 > ~/r1.txt
- 分別施於兩目錄,再用 diff 比較二輸出檔
- 通常我們用 cp -rp 來複製出完全相同(含檔案屬性權限)的另一目錄。
- 不適用於任一檔案本身及其對應,是否全同,其需再利用 checksum。
硬體資訊
- lshw
- lspci
- lspci -xxx
- dmidecode
- hwinfo
- cat /proc/cpuinfo
bash 字串處理
| 表示式 | 含義 |
| ${var} | 變數 var 的值, 與 $var 相同 |
| ${var-DEFAULT} | 如果 var 沒有被宣告, 那麼就以 $DEFAULT 作為其值(var 空值或非空不作處理) |
| ${var+DEFAULT} | 如果 var 空值或非空, 那麼就以 $DEFAULT 作為其值(沒宣告不作處理) |
| ${var:-DEFAULT} | 如果 var 沒有被宣告, 或者其值為空, 那麼就以 $DEFAULT 作為其值(非空不作處理) |
| ${var:+DEFAULT} | 如果 var 非空, 那麼就以 $DEFAULT 作為其值(var 沒宣告或空值不作處理) |
| ${var=DEFAULT} | 如果 var 沒有被宣告, 那麼就以 $DEFAULT 作為其值, 並賦值給 var |
| ${var:=DEFAULT} | 如果 var 沒有被宣告, 或者其值為空, 那麼就以 $DEFAULT 作為其值, 並賦值給 var |
| ${var OTHER} | 如果 var 宣告了, 那麼其值就是 $OTHER, 否則就為 null 字串 |
| ${var:OTHER} | 如果 var 被設定了, 那麼其值就是 $OTHER, 否則就為 null 字串 |
| ${var?ERR_MSG} | 如果 var 沒被宣告, 那麼就列印 $ERR_MSG |
| ${var:?ERR_MSG} | 如果 var 沒被設定, 那麼就列印 $ERR_MSG |
| ${!varprefix*} | 匹配之前所有以 varprefix 開頭進行宣告的變數 |
| ${!varprefix@} | 匹配之前所有以 varprefix 開頭進行宣告的變數 |
| ${#string} | $string 的長度 |
| ${string:position} | 在 $string 中, 從位置 $position 開始提取子串 |
| ${string:position:length} | 在 $string 中, 從位置 $position 開始提取長度為 $length 的子串 |
| $substring 可以是一個正規表示式 | |
| ${string#substring} | 從變數 $string 的開頭, 刪除最短匹配 $substring 的子串 |
| ${string##substring} | 從變數 $string 的開頭,刪除最長匹配 $substring 的子串 |
| ${string%substring} | 從變數 $string 的結尾,刪除最短匹配 $substring 的子串 |
| ${string%%substring} | 從變數 $string 的結尾,刪除最長匹配 $substring 的子串 |
| ${string/substring/replacement} | 使用 $replacement, 來代替第一個匹配的 $substring |
| ${string//substring/replacement} | 使用 $replacement, 代替所有匹配的 $substring |
| ${string/#substring/replacement} | 如果 $string 的字首匹配 $substring, 那麼就用 $replacement 來代替匹配到的 $substring |
| ${string/%substring/replacement} | 如果 $string 的字尾匹配 $substring, 那麼就用 $replacement 來代替匹配到的 $substring |
ACL 細部權限設置
多版本共存的入門可參考這篇討論文章
XZ 的一些用法
- 原則上壓縮效果優於 gzip
- xz [選項] [檔案]
- 只適用於單檔壓縮,且會刪除來源檔生成目的檔。所以多檔可搭配 tar 使用。
- 壓縮層級從 1 至 9,就直接以數字指定之。預設通常為 6。
- -[number] 壓縮層級
- -e 再加強壓縮品質,搭配壓縮層級
- -v verbose
- -d 解壓縮。解壓縮關聯不到核心數或執行緒數。
- -z 壓縮,或不指定亦表壓縮
- -k 保留來源檔
- -T[number] 使用最多 number 個執行緒,預設為 1;0 的話是指所有核心都可採用。
- 搭配 tar,參數是 J
- tar -Jcf abc.tar.xz {files}
- tar 下,若要指定壓縮層級,或執行緒數,則需使用參數(取代 J)例如 –use-compress-program=’xz -9T2’(注意 – -u)
以他人身份執行命令
- sudo runuser -l [user_name] -c ‘command’
- 參考
grep
- 以下列出使用時,該注意的地方
### 多行搜尋
## grep -z -o -P -a 通常一起出現
# P,使用延伸的 perl regex。Perl compatible regular expressions (PCRE) by using the -P flag。
# o,僅輸出所 match 者。否則 -z 將使全文全輸出/或採用 --color。
# a,有時候 grep 會誤判把文字檔視為二元碼檔來搜尋,且便不會有預期的結果輸出。故加 -a 來要求以文字檔型式來讀取。
# z,啟用多行搜尋。實際是將換行符號 '\n' 代換成 '\0',結果等同全文只成一行,因此 grep 遇不到 '\n' 便可實現多行搜尋。然而要注意以下幾點,
搜尋時,'\0' 被視為空白字元且佔位,但輸出時仍會換行並摘掉 '\0',見下例(a)。唯最後一筆字串輸出因其尾帶 '\0',grep 除了輸出換行,還保留該字元,以呼應 -z 選項,故,所輸出者之最後一個 byte 為 '\0',因之若後續處置將遇到其成二進位檔案屬性之問題。得用 tr 換回來,tr '\0' '\n'。
因此該注意佔位及檔尾結尾 '\0' 兩個重點。
# ex.(a) grep -zaP --color "(?s)(?<=\>)[[:space:]]?t[[:space:]]?(?=\<)" | sed '$s/\x0//'
>t
<
>t<
>
t<
唯有如此才能在多行搜尋下,把三個 t 都抓出來。可試將上式 sed 的取代後字元顯示出來(不加 $)便可看出唯有一個被取代了。
### 搜尋 main 函式進入點
## ./serf.sh ".*\.\(c\|cpp\)$" "(?s)(int|void)[[:space:]]*main[[:space:]]*\([^\)]*\)[[:space:]]*{ -izaP --color" | tr '\0' '\n' | grep "FoundHere"
# (a). 注意前面括號和 | 不能有脫離符號,後面括號必須有脫離符號
# (b). 若沒加 -a,則搜尋中可能就出問題;若沒加 tr,則後面搜尋就必成 binary code search。
# (c). (?s) activate PCRE_DOTALL, which means that . finds any character or newline
### lookahead & lookbehind & not-greedy
## (a). ./serf.sh ".*\.c$" "(?s)(?<=fitness).*(?=other) -aziP --color"
## (b). ./serf.sh ".*\.c$" "(?s)(?<=fitness).*?(?=other) -aziP --color"
# (a). greedy,在最後一筆 other 之前都歸屬 .* 的。下面 fitness & other 不會顯示出來。
/////FITNESS/////
* FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
* COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
* IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
* CONNECTION WITH THE SOFTWARE OR THE USE OR /////OTHER/////
# (b). not-greedy,.* 一旦遇到其後的 pattern 便停止;以 .*? 表示。下面 fitness & other 不會顯示出來。find . in non-greedy mode, that is, stops as soon as possible。
/////FITNESS/////
* FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
* COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR /////OTHER/////
# (c). (?<=keyword) lookbehind,在此關鍵字之後的都為 match。關鍵字排除在外,以有別於 grep 預設行為
# (d). (?=keyword) lookahead,在此關鍵字之前的都為 match。關鍵字排除在外,以有別於 grep 預設行為
# (e). lookbehind 關鍵字本身僅適用於固定長度字串/非 re(lookahead 無此限),否則使用 \K;而其作用是不再使用 look(x),而是緊接在某 re 後面重置 match,即,\K 之後的,才算 match。
/*
* FreeRTOS Kernel V10.0.0
* Copyright (C) 2017 Amazon.com, Inc. or its affiliates. All Rights Reserved.
*
* Permission is hereby granted, free of charge, to any person obtaining a copy of
* this software and associated documentation files (the "Software"), to deal in
* the Software without restriction, including without limitation the rights to
* use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
* the Software, and to permit persons to whom the Software is furnished to do so,
* subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in all
* copies or substantial portions of the Software. If you wish to use our Amazon
* FreeRTOS name, please do so in a fair use way that does not cause confusion.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
* FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
* COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
* IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
* CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
*
* http://www.FreeRTOS.org
* http://aws.amazon.com/freertos
*
* 1 tab == 4 spaces!
*/
### 特殊符號
\N find anything except newline, even with PCRE_DOTALL activated
\s 空白字元集合
\S 非空白字元集合